

Is friction always bad?
At Onfido, we’re creating an open world where identity is the key to access.
Since our goal is to prevent fraud while maintaining a great user experience for legitimate people, we launched advanced video biometric identity verification. With this approach to facial verification, we ask people to record live videos instead of static selfies. Users record themselves moving their head and talking out loud to prove they are real people.
This is the first version of our biometric video check.
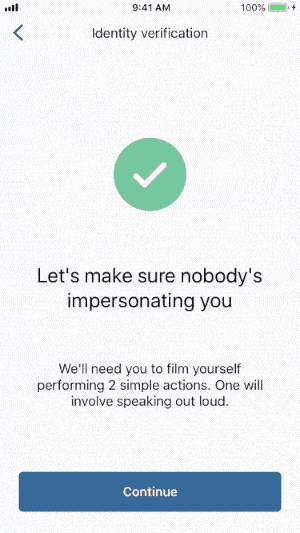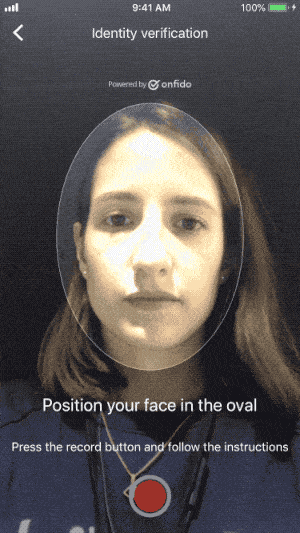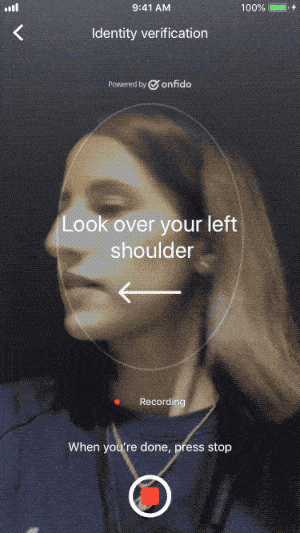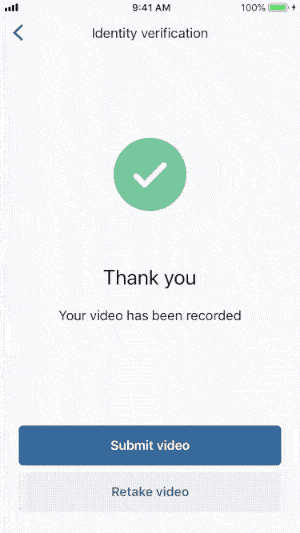
A handful of our customers adopted this new beta feature. But after a few weeks, we noticed that the videos were hard to process, making identity verification difficult. Users were not performing the right actions. They would retry multiple times and many eventually gave up. This meant that legitimate users, who would otherwise have a verified identity, were falling through the cracks.
We needed to find a solution, so over a Design Sprint, we talked to machine learning engineers, biometric specialists, mobile developers, product managers and UX designers.
Our goal was to radically improve our selfie video verification. We’ve documented our process to improve the selfie video feature. You can try it now on our demo app.
What went wrong?
The actions we asked users to perform while taking their selfie videos were designed for us to detect fraud accurately. What was wrong with the experience that made legitimate users get rejected?
We watched dozens of our users record selfie videos during usability testing, and finally came across two major problems.
- Taking a selfie is easy. Taking a selfie video is hard. To record their selfie video, users had to hold their phone up, press a button, speak out loud, press a button, move their head, press a button. And finally submit their video. That’s a lot of buttons to press, while keeping the phone up, moving and speaking at the same time.
- Users don’t know if they did it right or wrong. Users had to make movements in front of their phones that they never do normally. They had instructions to follow, but nothing to tell them if they were doing the right thing. At the end of the experience, users didn’t know if what they’d done was correct.
The actions we asked users to do have been designed for us to detect fraud very accurately. We couldn’t change the actions themselves, but we could improve the way we guided users through this process.
We decided to focus on helping users turn their head, as that’s where we saw the most mistakes. Improving the “say the digits out loud” action will be our next step.
Initial prototypes
At the end of our Design Sprint, we had two prototypes that we tested with users.
-
Prototype 1: we added an introduction screen before the selfie video to tell users what to do, and how to do it. When testing it, we saw less users struggling: they were recording good quality videos with the correct movements. Moreover, we saw an improvement in the feeling of trust from our users. But some people skipped this screen, as they wanted to start recording their video straight away.
-
Prototype 2: we showed instructions on the camera screen to help users while they were recording their video. Most users were happy about those instructions that comforted them when performing the required actions. However, some people missed them: they were focusing on looking at their face on the screen, and nothing else. The instructions on the camera screen provide in-context help, but some users focus on their actions and prefer feedback to instructions.
The solution
Those two prototypes became our starting point to craft our final solution.
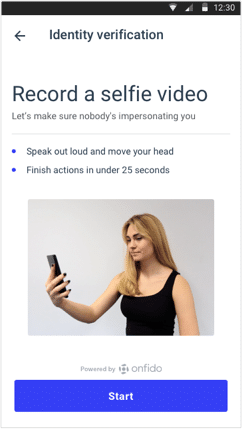
Introduction screen
We created an introduction screen, and we kept it light. And we recorded tutorial videos to show users performing the actions.
We recorded multiple videos to showcase different users demonstrating our feature. The video presented to a specific user is picked up randomly from a set of several videos.
We’ve also started detecting users’ faces. When users are correctly positioned in front of their phone, their face is detected and the video recording starts automatically. It’s a good way for users to be sure they’re correctly positioned.

Hello, your face is detected
We’ve also added a playback of the recorded video for users to review it before submitting. This gave people more control over their image. It also helped get rid of a large amount of failed videos, before they were sent to us for identity verification.

That’s a good video, ready to submit!
Overall, we’ve added more visual and haptic feedback to help users turn their head correctly.
So to improve our selfie video feature, we’ve added new screens to the experience, more text to read and a video to watch. This made the video longer to record than before.
Our users usually sign up to a service and need their identity verified during this process. The time spent on our experience is added to the time spent on the sign up and mobile verification process. More time on our side can increase fatigue exponentially.
So… you made the experience longer, isn’t that increasing drop-off?
This is a common piece of feedback we received when we started sharing our solution.
More friction = drop-off
More time spent on the task = drop-off
Those are very common hypotheses that we wanted to test. Through user testing, we were surprised to find that users were willing to trade time for a better experience and transparency. We found out that better instructions and a more robust capture process were a game changer for our overall experience.
People would trust the software more, they would be more confident about what they’re doing and they wouldn’t feel fatigued. They perceived the time spent on the task as equal to or lower than the previous version.
We’ve added steps to our experience, and more time to spend on screens before, during and after the video capture. But instead of creating fatigue and seeing users drop off, we helped them to prevent mistakes. Our solution led to fewer retries, and it made users trust our product more.
We added friction, but it’s the price to pay to help users achieve their goals in a comforting and secure way.
When asking users to share very personal data to allow them to access a service, perceived speed and effective speed are very different. Each step we added brought transparency and reinforced our users’ trust in our identity verification.
How are we facing up to building trust with today's customers? Learn about customer attitudes to biometric verification.







