
Machine learning for identity verification
At Onfido, an Entrust company, we use machine learning (ML) to build remote identity verification systems. If a bank wants to allow users to open bank accounts digitally, from their phones, while satisfying KYC requirements, the bank needs to know who the user is. This is where IDV vendors, such as Onfido enters the picture. We ask users to take a photo of their government-issued ID and take either a photo/selfie or video of themselves.
We then use ML to answer four questions:
- Does the selfie and the document show the same person?
- Is there a live person in the selfie or is it an impersonation attempt, such as a deepfake?
- Is the image of a genuine identity document or does it show signs of fraud?
- What is the personal data written on the document, i.e., name, date of birth, etc.?
The biometric problems of face recognition and liveness detection are challenging with the need to detect ever more realistic looking deepfakes while reducing demographic bias at the same time.
Document verification faces different challenges, with the key feature being the sheer number of different document types in the world. Each country has its own passport, driving license, identity card, and residence permit; and new versions of these documents are being issued every few years. The total number of documents in circulation worldwide is measured in the thousands. To keep it simple, we assume that we want our identity verification system to support 2,000 document types.

Document extraction at high accuracy
Here, we will take a closer look at the problem of extracting data from document images. Given an image of an ID document, we want to know the name, date of birth, document number, etc. that are shown in the document. For a bank, this is key information to establish the identity of the new customer and thus the extraction system needs to be both reliable and accurate.
We can imagine several approaches to the problem.
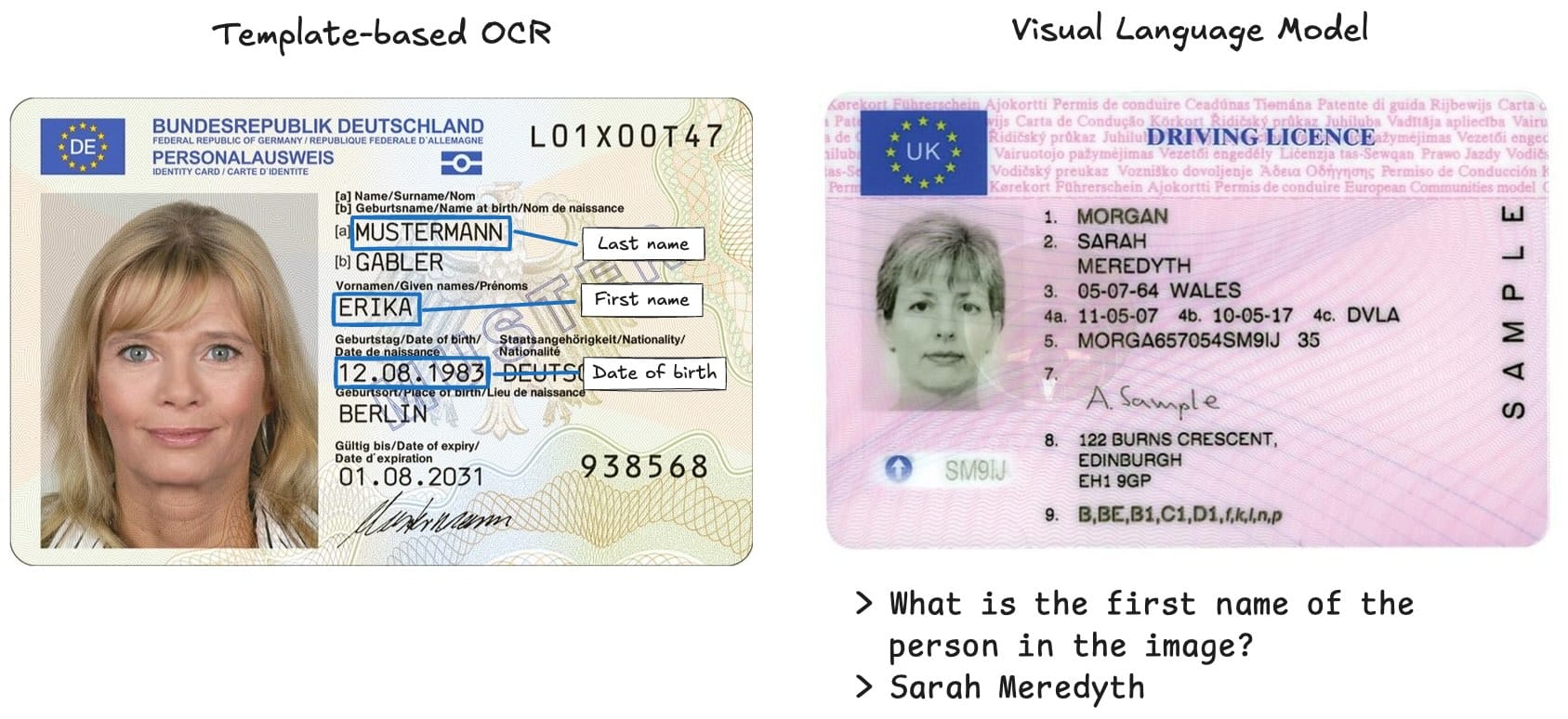
Identity documents are very regular. Within a single document type, data fields will always be in the same position relative to the document. We can leverage this regularity and annotate the location of data fields with bounding boxes in a template and, after aligning the input image to the template, apply an OCR algorithm to that region. This method will work, but it will hit a performance ceiling when we realize that some document types are less regular than others: fields, particularly the address field, can span multiple lines and field alignment can be variable, both in the horizontal and vertical.
On the other end of the spectrum, we could use the vision capabilities of one of the large vision language models and upload the document image together with a prompt such as “What is the name of the person in this identity document?” And while this method will have an extraction accuracy that is reasonable for a proof of concept, it will not reach the 98%+ accuracy that our clients expect from a production system.
To achieve the extraction accuracy we require from our product, we need to train our own models. In the last years, several foundation models for document understanding and visual question answering have been released: Dessurt, Donut, Pix2Struct, LayoutLM. These models all share a similar architecture.
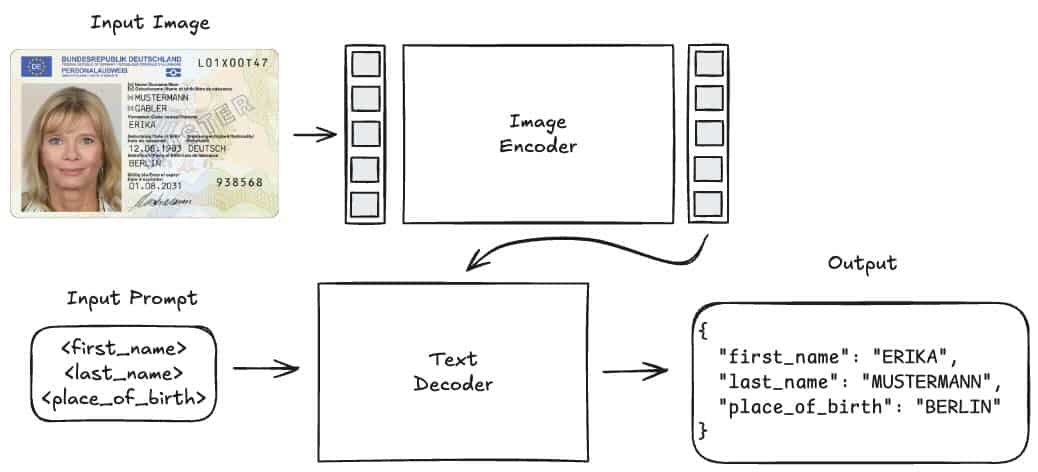
The model inputs are an image and a text prompt. The image is encoded by a vision transformer and the resulting embedding together with the prompt are fed into a decoder that produces the desired output.
In our use-case, the input is a document image, and the prompt is the list of data fields that we would like to extract. The output is a structured JSON string with the field values.
Scaling document extraction
So now we have a medium-size model, 250M parameters, 1GB when saved on disk and we have training data for fine-tuning for each of 1,000 document types. Now, while I casually say "we have", of course gathering and cleaning the data for the 1,000 document types is absolutely a non-trivial effort. In machine learning we have and always will spend 80% of our time on data and 20% on models... In any case, now we have options:
- Train one model on the joint 1,000 document type dataset
- Train 1,000 models: one model per document type
- Find an intermediate solution: 50 models with one model per 20 document types
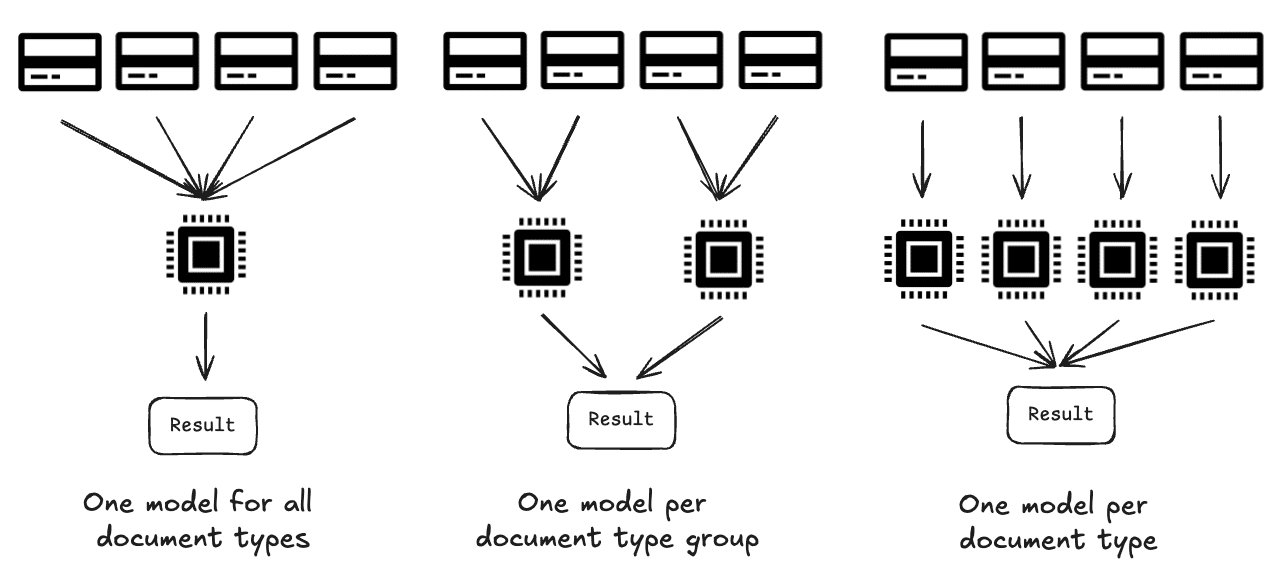
As we move along this spectrum from left to right, we buy flexibility by paying with additional complexity. The solution on the left is the simplest one: only one model needs to be trained, only one model needs to be deployed. But it is also the most rigid solution: to support an additional document type, the whole model needs to be retrained; a process that can take several days of training time.
On the right, we have the most flexible solution. Each model is responsible for an individual document type. If we want to support another document type, we simply train another model. And compared to the other end of the spectrum, this training will be fast, because we only need data from a single document type.
The middle of the spectrum tries to compromise between the two extremes: grouping document types and training.
Before embarking on the journey that prioritizes flexibility, we should always ask whether flexibility is worth the price. For us the answer was clear: it’s important not only to be able to quickly add support for additional document types or additional fields to be extracted, but also to be able to do that safely without impacting performance on all already supported documents.
And now we arrive at the question that motivated the talk: How do we serve 1,000 medium-sized models in production? A single GPU node can fit up to four models. Which means we would need 250 GPU nodes, more if we want redundancy. This leads to two problems: First, GPUs cost money; provisioning 250 GPUs on AWS will cost >$100k/month. But even if we were willing to pay this money, we might not be able to get the GPUs. GPUs are scarce, even on AWS.
Enter LoRA
Low-Rank Adaptation (LoRA) is a parameter-efficient fine-tuning method. The idea of LoRA is as follows: when fine-tuning a model, instead of learning all parameters of a weight matrix directly, we only learn low-rank updates to the matrix as follows.
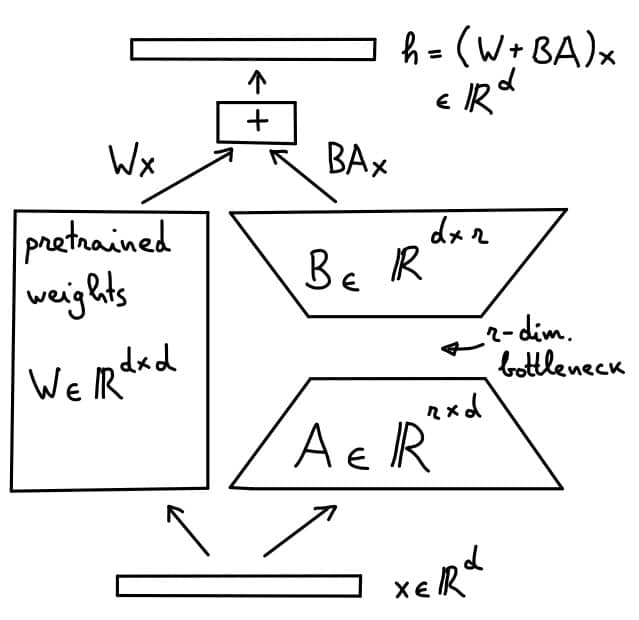
Let us consider an ordinary linear layer in the model,
h=Wx
with W in R^{d\times d} a weight matrix, and x, h in R^d the layer inputs and outputs. LoRA modifies the layer to
h = (W + AB)x
with ‘A’ in R^{r \times d}, ‘B’ in R^{d \times r} and r <<d a hyper-parameter. Then, as the rank of ‘AB’ is at most r, the matrix ‘AB’ is a low-rank update to ‘W’. During LoRA training, we keep ‘W’ constant and only learn the matrices ‘A’ and ‘B’, thus reducing the number of trainable parameters from d^2 to 2rd. A common choice for the rank is r=4 or r=8. In a ViT base model, we have d=768, so this results in 96- or 48-fold reduction in the number of trainable parameters for the linear layer.
We apply this method to layers throughout the network. In a transformer architecture we can adapt the ‘Q’, ‘K’ and ‘V’ projection layers in each attention head, the linear layer merging attention heads together as well as the post-attention MLP layer. Going beyond transformers, with small modifications, LoRA can also be applied to convolutional layers.
Even though the number of trainable parameters can be as low as ~1% of the trainable parameters of the full model, in many problems LoRA fine-tuning reaches almost the same accuracy as fine-tuning the full model. Intuitively, this is because we can modify all parameters of the model throughout all its layers. The training molds the whole model into the right shape for the problem. We can contrast LoRA with a traditional “low parameter fine-tuning method”, where we fine-tune only the last few layers of the model, while keeping all other layers frozen; the number of trainable parameters might be comparable to LoRA, but their effect is much more limited, since most of the model remains rigidly frozen and only a small part is being adapted to the problem.
The collection of all low rank updates to a model is called an adapter and storing an adapter takes only ~1% of the memory required by the full model. While pre-LoRA we could fit only 4 full models on one GPU, we can now fit one base model together with several hundred adapters. The same GPU that previously could support inference for four document types, can now support inference for several hundred document types. In short, we have eliminated the GPU bottleneck from our system.
LoRA in practice
The practical implementation of LoRA is made easy using the PeFT library, short for Parameter-efficient Fine-Tuning) together with the Transformers library. . Adapting a model for LoRA training can be as simple as
import peft, timm
model = timm.create_model("convnext_base", nu)
config = peft.LoraConfig(
r=4,
target_modules=r".*\.conv_dw|.*\.mlp\.fc\d",
modules_to_save = ["head.fc"],
)
peft_model = peft.get_peft_model(model, config)
We use a regex to select, which layers should be targeted by LoRA training. In this case we target all depthwise convolutional and all fully connected layers. We also perform a full fine-tuning on the classification head.
>>> peft_model.print_trainable_parameters() trainable params: 4,341,770 || all params: 91,918,484 || trainable%: 4.7235
These choices result in a model that has only 4.7% of the trainable parameters of the full model.
After implementing LoRA training and training a first model, we may find that the accuracy of the LoRA model does not quite reach the level of a fully fine-tuned model. In other words, it might be time for some hyper-parameter tuning.
- Two key factors that influence both accuracy and the size of the adapter are the rank r, and the choice of which layers to adapt. A good rule of thumb is to start by adapting all linear layers and then tune r to get the desired accuracy/adapter size trade-off.
- The original LoRA paper includes a scaling parameter alpha, which acts on the update matrices viah = (W + \alpha / r AB)x. Empirically, alpha=2r, appears to be a good choice, but Sebastian Raschka has found that sometime tuning alpha can improve performance.
- We have observed that training a LoRA adapter requires about twice the number of epochs compared to regular fine-tuning to achieve the same accuracy. More recently, authors XYZ (arXiv:2402.12354) have applied theoretical insights on large width networks to show that by using different learning rates for the ‘‘A’ and ‘B’ matrices, we can reduce the training time to values comparable to regular fine-tuning.
If the need for even smaller adapters arises, then there are methods such as VeRA or LoRA-XS that reduce the trainable parameter count even further.
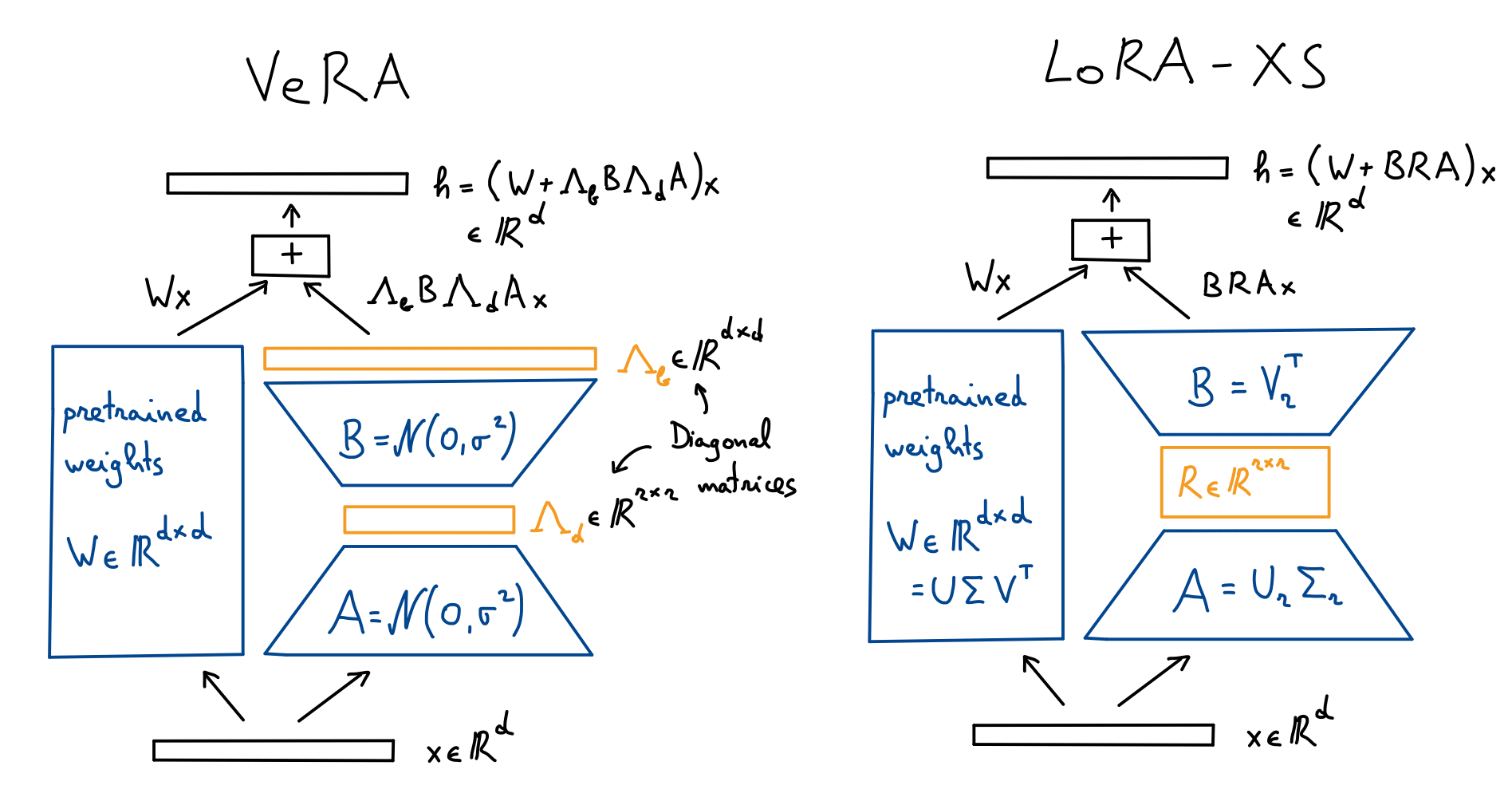
For example, VeRa, freezes the matrices ‘A’ and ‘B’ after random initialization and shares them across layers. Instead VeRA only trains diagonal scaling matrices Lambda_d and Lambda_b.
LoRA-XS follows the same idea, but instead of initializing ‘A’ and ‘B’ randomly, it uses the singular value decomposition of the weight matrix ‘W’. The trainable parameters are
contained in the r-x-r matrix ‘R’. One feature of this method is that the number of trainable parameters does not scale with the size of the weight matrix W, i.e., it is independent of d.
In our application we didn’t have to search beyond standard LoRA adapters, but there is a large amount of literature available, if we had to.
Examine the importance of identity verification processes and their role in facilitating key business objectives in this Guide to Digital Identity Verification.
Takeaways
Training LoRA adapters instead of fine-tuning the full model and deploying many adapters alongside a single base model has enabled us to scale up model deployment and overcome GPU scarcity and spiraling costs. But LoRA is not a silver bullet. To support 2,000 document types, we still need to curate 2,000 datasets, train 2,000 models, track their performance and deploy 2,000 models to production. Orchestrating and automating this process is still a formidable engineering challenge that our team at Onfido is currently tackling.
Please note, this blog describes work done at Onfido1 by the data extraction team and was presented as a talk at the first AI Engineer Meetup.
1 While Onfido has been acquired by Entrust, the majority of the work described here was carried out before the acquisition.







