Digital identity
made simple
Create trust at onboarding and beyond with a complete, AI-powered digital identity solution built to help you know your customers online. Automation allows you to acquire new customers and reduce costs while meeting global KYC and AML compliance.
Digital identity
made simple
Create trust at onboarding and beyond with a complete, AI-powered digital identity solution built to help you know your customers online. Automation allows you to acquire new customers and reduce costs while meeting global KYC and AML compliance.
Trusted by 1000+ global businesses


How can Onfido
help your business?
Onboard more customers
Make a great first impression using our Smart Capture SDK with automated identity verification powered by Atlas™ AI.
Navigate compliance
Satisfy global and local regulatory compliance, including KYC, AML, and age verification requirements.
Prevent advanced fraud
Stop identity fraud using award-winning document and biometric verifications, data sources, and passive fraud detection signals.
Reduce cost and complexity
Automate onboarding to reduce the cost of customer acquisition. It’s easy to orchestrate journeys that make verification simple.
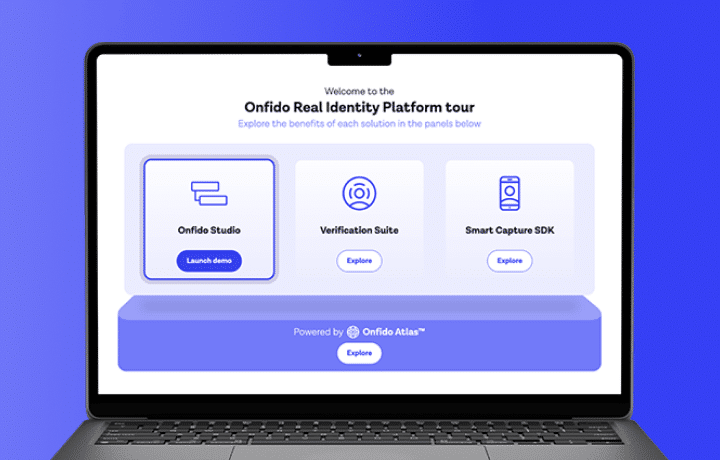
Our solution
The Real Identity Platform
Put digital trust at the core of every customer interaction. Powered by fast, fair, and accurate AI, the Real Identity Platform brings together a global suite of identity verifications and signals into an easy-to-use orchestration studio.
Real Identity Platform tour
Product innovation
Flexible compliance package
Meet complex local regulatory needs and remotely onboard customers across Europe with an off-the-shelf compliance solution. Onfido’s Compliance Suite combines ETSI-certified identity verification with Qualified Electronic Signature (QES) and One-time Password (OTP) to offer simple, seamless, and eIDAS-compliant onboarding.
Developer resources
Built by developers for developers
Take advantage of detailed documentation, product guides, API libraries, and reference materials that help you get up and running with ease.
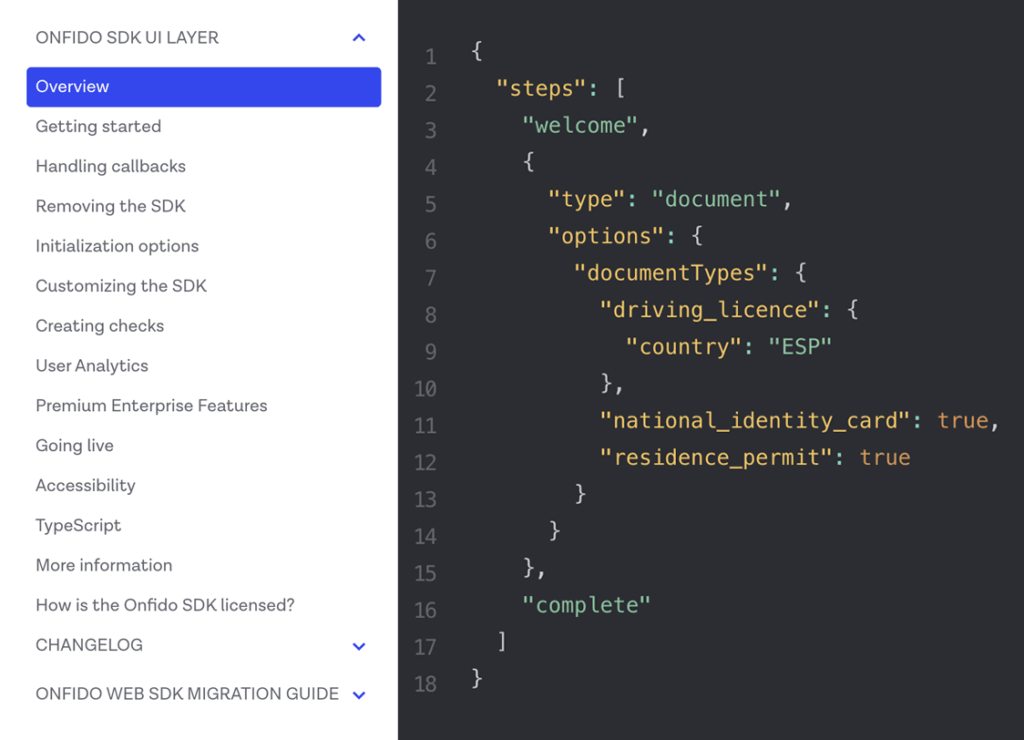
Developer Hub
Get everything you need to configure and integrate with the Onfido Real Identity Platform.
API reference
Make integration quick and efficient using our comprehensive technical reference guides.
Professional Services
Our integration and success teams’ mission is to deliver maximum value for our customer.
Recognized as a leader
With more than a decade of identity verification, fraud detection, and AI development experience, Onfido is recognized as a global technology leader providing automated digital identity and authentication solutions.






Best Innovation in Computer Vision
CogX 2023

We required a quick, tactical solution that did not involve expensive IT engineering costs. Onfido Studio was perfect as it was an ‘off-the-shelf’ product that we could plug into our application process but without integrating it fully into our mainframe systems.
Darren Prescott, Senior Manager Current Accounts & Credit Cards, The Co-Operative Bank

Partnering with Onfido has helped us deliver a premium onboarding experience for new customers while enabling us to meet strict KYC requirements. The sheer scale of Onfido’s identity verification has accelerated our strategic growth targets, supporting over 40,000 identity checks daily.
Hasan Luongo, VP of Global Marketing, Chipper Cash
Read the Chipper Cash story
We want to give every customer a quick set-up, a smooth experience, and powerful credit access. That starts at onboarding — with Onfido, we have a fast, accurate, and human-less way to verify our customers, enabling our compliance at scale.
Eric Suen, Vice President of Technology, DBS
Read the DBS Bank story
With Onfido Studio, Access Group is creating a superior user journey, modifying the way candidates can prove their identity digitally. We went to full production in just four weeks, providing over 3,000 identity verification checks for Right to Work screenings in the two weeks that followed, with the agility of Studio to scale our operation.
Colin Whipp, Head of Account Management, The Access Group
Read The Access Group story
We're pleased to be part of this new approach, powering background checks and screening thanks to our partnership with Onfido. By providing the highest levels of identity proofing, applicants are able to prove their status and manage onboarding processes wherever they are and at a time to suit them. The days of photocopying and in-person manual review are now in the past.
Callum Murray, CEO, Amiqus
Read the press release
What’s new?
Keep up to date with identity insights and resources






Ready to get started?
Our identity experts are available to talk through your requirements, answer questions, and set up a demo.

